For many years now Git has been the SCM (source control management aka version control) of choice. It offered many features which alternatives such as CVS did not, and combined with GitHub website created an entire CI pipeline which any teams Dev practices could be built around.
When I began reading about the mechanics of Git it was obvious that it's combination of many different techniques, all of which produce the "replicated versioned file system" know as Git, for example:
- Linked lists,
- File system objects database
- Hashing (stat SHA-1 vs content SHA-1 vs content Deflate)
- Differential encoding
So I decided to create a mini-working version with some of the core version control features. Thankfully there are many helpful books which break down how things work, so I have attempted to strip the internals down to its bare minimum.
This post will focus on:
- repositories,
- working directories,
- staging,
- committing
- status checks.
I have omitted packfiles, deltas, branches, tags, merging and comparing staged chunks (diffing). I may do a follow up post/repository on those.
This is part of my "under-the-hood of" series:
- GraphQL
- Web bundlers (e.g. Webpack)
- Type systems (e.g. TypeScript)
- Test runners (e.g. Mocha)
- Source maps
- React hooks
- Apollo
- Auto formatters (e.g. Prettier)
A video for this talk can be found here. Part of my "under-the-hood of" series here.
The article today will be broken down into:
1: Overview
Git is described as a distributed version-control system, which tracks changes in any set of files. It was initially released 15 years ago (in 2005) and has grown in functionality and popularity massively since then. As any developer who uses Github knows (or an alternative e.g. BitBucket/GitLab) it has become a staple in the world of software as a best practice.
Workflow
I am not going to review how it is used but the basic workflow can be summarised by:
- initialise a new git repository
- A file/s change is made locally and saved
- The file/s is added to staging
- The file/s in the staging area are comitted
- The commit is pushed to a remote repository (pulling the latest before doing so).
We will break down each step, but before we do we need to review the mechanism at the core of Git, the "Object model".
Object model
The object model is essentially an incredibly efficient versioned file system (with replication).
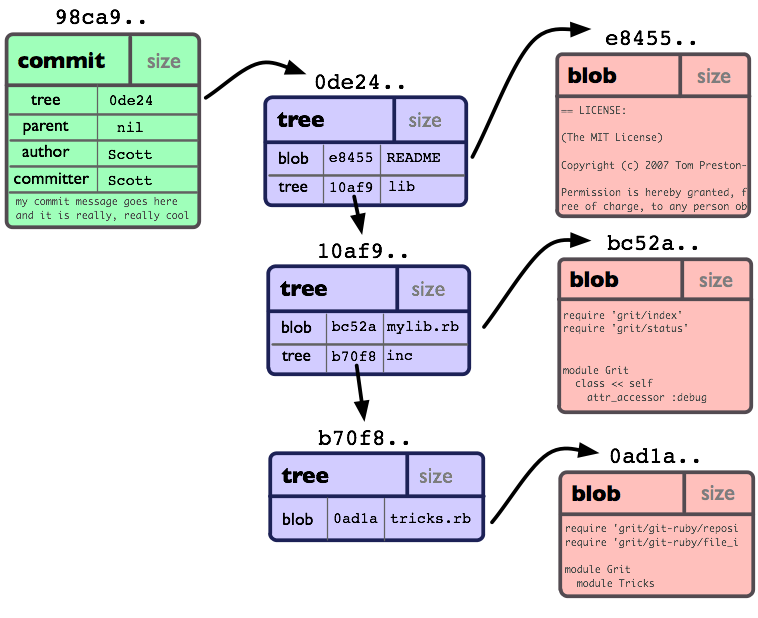
Each file in the repository exists in the file system and the object database. The object database is a hash of the contents. A hash is an object, there are 4 types in total but today we will look at (excluding "tags"):
- Blob -> a sequence of bytes. A blob in Git will contain the same exact data as a file, it’s just that a blob is stored in the Git object database. Basically the file contents.
- Tree -> corresponds to UNIX directory entries. Can contain blobs or sub trees (sub directory). The commit tree has the entire project in blob and trees at time of the commit. It can recreate the entire project from that tree. Always from root directory even if a sub directory file is being updated in the commit.
- Commit -> single tree id and commits preceding it
Each tree node, commit and file have their own unique 40 character long SHA-1 representation. The filename is a hash of the contents. If the contents change, so does the hash. Each time it changes a new entry/hash is added but keeps the old ones.
Inside a git repository they are found under the .git/objects folder.
This is my favourite image to describe the structure.
Hash
Within the object model, the filename is a 2-way SHA-1 encoding of the contents.
Git prefixes any Blob objects with blob, followed by the length (as a human-readable integer), followed by a NUL character
Example:
> s='abc'
> printf "$s" | git hash-object --stdinEquivalent to
> printf "blob $(printf "$s" | wc -c)\0$s" | sha1sumObject file contents are compressed via DEFLATE zlib algorithm, it is less human readable or filename-friendly but a more efficient encoding.
Components
I will be covering the components we will be building in our mini-working version.
Working directory
The current system folder with git repository in, also known as the working tree.
HEAD
A file holding a ref to current working branch. Basically the last checked out workspace. It holds a reference to the parent commit, usually last branch checked out.
Found in the file .git/HEAD.
Example
> ls .git/HEAD
ref: refs/heads/master
> ls .git/refs/heads/master
2e1803ee08fa9aa36e4c5918220e283380a4c385Branches
A branch is actually just a named pointer to specific snapshot. When it is checked out
- moves HEAD pointer to point to the feature ref (branch)
- moves all content from the current branch repo into the index file, so it's easy to track changes.
- Make working dir match content of commit pointing to (using tree and blob objects to update working dir contents)
Tags
An alias for a commit id. The HEAD will point to the latest or predefined e.g. .git/refs/heads/tags/<tag_name>
Repository
A git project stored on disk i.e. not in-memory. Essentially a collection of objects.
Staging
Area between working directory and repository. All changes in staging will be in the next commit.
Index file
The index is a binary file, it does not hold objects (blobs/trees), it stores info about files in repository. It is a virtual working tree state.
The index file is located at .git/index. You can see the status of the Index file via > git ls-files --stage
Information stored
For each file it stores
- time of last update, name of file,
- file version in working dir,
- file version in index,
- file version in repository
File versions are marked with checksums, a SHA-1 hash of stat(), not a hash of the contents. This is more efficient.
Refresh
It is updated when you checkout a branch or the working directory is updated. Runs in the background automatically.
Hashing
It uses uses a filesystem stat() to get the files information, to check quickly if the working tree file content has changed from version recorder in index file. Checks the file modification time under st_mtime.
The refresh literally calls stat() for all files.
Additional reading
The main goal of this post is the mini-working version below so we have only just touched briefly on how git works. Here are websites which go into far more details
2: Building our own Git
our git code
The code consists of 4 files, one for each command, plus a util.
init.mjsstatus.mjsadd.mjscommit.mjsutil.mjs
init.mjs
// imports excluded, see linked repo for details
const init = () => {
const workingDirectory = workingDir()
const files = glob.sync("**/*.txt", { cwd: workingDirectory }) // (1)
const indexData = files.reduce((acc, curr) => { // (2)
const hash = hashFileStats(curr)
acc[curr] = {
cwd: hash,
staging: "",
repository: "",
}
return acc
}, {})
fs.mkdirSync(`${workingDirectory}/.repo`) // (3)
updateIndex(indexData)
fs.writeFileSync(`${workingDirectory}/.repo/HEAD`) // (4)
fs.mkdirSync(`${workingDirectory}/.repo/objects`) // (4)
}(1) Grab all the files from the current working directory
(2) Build the index file using files stat() SHA-1 hash for each file
(3) Write a repository folder under .repo
(4) Inside repository write a HEAD file and objects folder
status.mjs
// imports excluded, see linked repo for details
const status = () => {
const indexData = getIndexData() // (1)
const notStaged = []
const notComitted = []
const updatedIndexData = Object.keys(indexData).reduce((acc, curr) => { // (2)
const hash = hashFileStats(curr) // (2a)
if (hash !== indexData[curr].cwd) { // (2b)
acc[curr] = {
cwd: hash,
staging: indexData[curr].staging,
repository: indexData[curr].repository,
}
notStaged.push(curr)
} else {
if (indexData[curr].cwd !== indexData[curr].staging) {
notStaged.push(curr) // (2c)
} else if (indexData[curr].staging !== indexData[curr].repository) {
notComitted.push(curr) // (2d)
}
acc[curr] = indexData[curr]
}
return acc
}, {})
updateIndex(updatedIndexData) // (3)
console.log("\nChanged locally but not staged:")
notStaged.map(message => console.log(`- ${message}`)) // (4)
console.log("\nStaged but not comitted:")
notComitted.map(message => console.log(`- ${message}`)) // (5)
}(1) Grab the index data
(2) For each item in the index data
(2a) Grab files stat() SHA-1 hash
(2b) If doesnt match current working dir stored hash of file, flag as changed not staged
(2c) If does match above but doesnt match staged, flag as not staged
(2d) If does match staged but not repository, flag as not comitted
(3) Update index file
(4) Output local changes not staged
(5) Output staged changes not comitted
add.mjs
// imports excluded, see linked repo for details
const add = () => {
const workingDirectory = workingDir()
const files = process.argv.slice(2) // (1)
const indexData = getIndexData()
console.log("[add] - write blob objects")
const updatedFiles = files.map(file => {
const blobHash = hashBlobContentsInFile(file) // (2)
const blobDir = blobHash.substring(0, 2)
const blobObject = blobHash.substring(2)
// TODO - check exists first - for re-adding file with earlier contents
fs.mkdirSync(`${workingDirectory}/.repo/objects/${blobDir}`)
const blobCompressed = compressBlobContentsInFile(file) // (3)
fs.writeFileSync(
`${workingDirectory}/.repo/objects/${blobDir}/${blobObject}`,
blobCompressed
)
const hash = hashFileStats(file) // (4)
return {
file,
hash,
}
})
const updatedIndexData = Object.keys(indexData).reduce((acc, curr) => { // (5)
if (!updatedFiles.find(item => item.file === curr)) { // (5a)
acc[curr] = {
cwd: indexData[curr].cwd,
staging: indexData[curr].staging,
repository: indexData[curr].repository,
}
return acc
}
acc[curr] = {
cwd: indexData[curr].cwd,
staging: updatedFiles.find(item => item.file === curr).hash, // (5b)
repository: indexData[curr].repository,
}
return acc
}, {})
updateIndex(updatedIndexData) // (6)
}(1) Explicitly give files e.g. one.txt and two/three.txt
(2) For each file, get contents in SHA-1 and use for directory name and filename
(3) Get DEFLATED value and use for content
(4) Get SHA-1 value for files stat()
(5) Update the index
(5a) If file was not touched, just proxy values
(5b) If file was touched, update staging for the file
(6) Override old index data with new index data
commit.mjs
// imports excluded, see linked repo for details
// array of dir (name) and files (children), ordered by bottom-up
const _buildTree = paths => {
return paths.reduce(
(parent, path, key) => {
path.split("/").reduce((r, name, i, { length }) => {
if (!r.children) {
r.children = []
}
let temp = r.children.find(q => q.name === name)
if (!temp) {
temp = { name }
if (i + 1 === length) {
temp.type = "blob"
temp.hash = hashBlobContentsInFile(path)
} else {
temp.type = "tree"
}
r.children.push(temp)
}
return temp
}, parent)
return parent
},
{ children: [] }
).children
}
const commit = () => {
const workingDirectory = workingDir()
const indexData = getIndexData()
// TODO - if comitted already then dont recreate tree?? PROB chek first
const paths = Object.keys(indexData).filter( // (1)
item => indexData[item].staging || indexData[item].repository
)
const rootTrees = _buildTree(paths) // (2)
const flattenedTrees = rootTrees.reverse().reduce((acc, curr, key) => { // (3)
if (curr.children) {
const hash = createTreeObject(curr.children) // (3a)
const clone = Object.assign({}, curr)
delete clone.children
clone.hash = hash
acc.push(curr.children) // (3b)
acc.push([clone])
} else {
acc[key].push(curr) // (3c)
}
return acc
}, [])
const rootTree = flattenedTrees.reverse()[0]
const treeForCommit = createTreeObject(rootTree) // (4)
const parent = getParentCommit()
const commit = { // (5)
tree: treeForCommit,
parent: parent === "undefined" ? null : parent,
author: "CRAIG", // hardcoded for now
committor: "CRAIG",
message: "Initial commit",
}
const commitHash = createCommitObject(commit) // (6)
const updatedIndexData = Object.keys(indexData).reduce((acc, curr) => { // (7)
const { cwd, staging, repository } = indexData[curr]
let updatedRepo = repository
if (staging !== repository) { // (7a)
updatedRepo = staging
}
acc[curr] = {
cwd: indexData[curr].cwd,
staging: indexData[curr].staging,
repository: updatedRepo,
}
return acc
}, {})
updateIndex(updatedIndexData)
fs.writeFileSync(`${workingDirectory}/.repo/HEAD`, commitHash) // (8)
}(1) Grab files of files to commit
(2) Build tree for files in staging or comitted, excluded working dir only
(3) Iterate items root "tree" into a flattened array of trees
(3a) If tree, create tree for children
(3b) Then add children to flattened tree
(3c) If not a tree, push with previous tree
(4) Create tree object for root
(5) Create commit object, using parent commit if exists and the tree hash
(6) From commit object get commit hash
(7) Update index file
(7a) If staging hash does not match repository hash then update. An existing file has been updated.
(8) Update HEAD with the latest commit
utils.mjs
I have included the helper file but hopefully the names are pretty self-explanatory.
The largest is createTreeObject and createCommitObject. Both of which:
- Process given contents into a hash
- Compress given contents
- Writes compressed contents to the respective directory and file - The first 2 characters of a hash become the directory and the rest the filename.
import fs from "fs"
import crypto from "crypto"
import zlib from "zlib"
export const workingDir = () => {
const cwd = process.cwd()
return cwd + "/src"
}
export const sha1 = object => {
const string = JSON.stringify(object)
return crypto
.createHash("sha1")
.update(string)
.digest("hex")
}
const getFilePath = file => {
const workingDirectory = workingDir()
return `${workingDirectory}/${file}`
}
const getContentsInFile = file => {
const path = getFilePath(file)
return fs.readFileSync(path, { encoding: "utf-8" })
}
export const compressBlobContentsInFile = file => {
const contents = getContentsInFile(file)
return zlib.deflateSync(contents)
}
// always same based on contents
export const hashBlobContentsInFile = file => {
const contents = getContentsInFile(file)
return sha1({ type: "blob", contents })
}
// different based on midified time
// remove atime + atimeMs which are different each stat() call
export const hashFileStats = file => {
const path = getFilePath(file)
const contents = fs.statSync(path)
delete contents["atime"]
delete contents["atimeMs"]
return sha1(contents)
}
export const getIndexData = () => {
const workingDirectory = workingDir()
return JSON.parse(
fs.readFileSync(`${workingDirectory}/.repo/index`, { encoding: "utf-8" })
)
}
export const updateIndex = indexData => {
const workingDirectory = workingDir()
fs.writeFileSync(`${workingDirectory}/.repo/index`, JSON.stringify(indexData))
}
// hash contents, create tree, return hash
export const createTreeObject = contents => {
const contentsClone = Object.assign([], contents)
const flatContents = contentsClone.map(item => {
delete item.children // dont need full children depth
return item
})
const workingDirectory = workingDir()
const stringContents = JSON.stringify(flatContents)
const treeHash = sha1(stringContents)
const treeDir = treeHash.substring(0, 2)
const treeObject = treeHash.substring(2)
const treeCompressed = zlib.deflateSync(stringContents)
// create tree object
fs.mkdirSync(`${workingDirectory}/.repo/objects/${treeDir}`)
fs.writeFileSync(
`${workingDirectory}/.repo/objects/${treeDir}/${treeObject}`,
treeCompressed
)
return treeHash
}
export const createCommitObject = contents => {
const workingDirectory = workingDir()
const stringContents = JSON.stringify(contents)
const commitHash = sha1(stringContents)
const commitDir = commitHash.substring(0, 2)
const commitObject = commitHash.substring(2)
const commitCompressed = zlib.deflateSync(stringContents)
// create commit object
fs.mkdirSync(`${workingDirectory}/.repo/objects/${commitDir}`)
fs.writeFileSync(
`${workingDirectory}/.repo/objects/${commitDir}/${commitObject}`,
commitCompressed
)
return commitHash
}
export const getParentCommit = () => {
const workingDirectory = workingDir()
return fs.readFileSync(`${workingDirectory}/.repo/HEAD`, {
encoding: "utf-8",
})
}Testing it works
I wrote a small project to test the version control. 3 files each with a line of text, 2 of which inside a folder.
The above scripts are found inside bin/
A working directory / application is found in src/
one.txttwo/three.txttwo/four.txt
Then I wrote some inegration tests (test/index.integration.spec.js) to help track what happens to our repository for a given command, the steps (and results) are:
repo:init=> created INDEX with current working directory filesstat()hashrepo:status=> flag 3 new local changes not staged (those above)-
repo:add one.txt two/three.txt=>- should create blob objects, inside 2 character-long directories, with content compressed
- should update INDEX, move items to staged
repo:status=> flag 1 new local changes not staged and 2 changes not comitted- Manually update
one.txt repo:status=> similar to previous except now flagsone.txtas locally changedrepo:add one.txt=> re-add updated fileone.txtshould update blob objectrepo:status=> re-added file should show with old added filerepo:add two/four.txt=> addtwo/four.txtso 2 items in tree objectrepo:commit=> should create tree and commit object and update HEAD and INDEX
What have we missed?
As mentioned there are many additional parts to the real Git version control which we have omitted from our library. Some of those are:
- Comparing change chunks (diffing)
- Packfiles
- Deltas
- Branches
- Tags
- Merging
Thanks so much for reading, I learnt a huge amount about Git from this research and I hope it was useful for you. You can find the repository for all this code here.
Thanks, Craig 😃